
robots.txtとは、検索エンジンのクローラーの動きを管理(制限)するための、クローラーに対する命令文が記載されたものです。クローラー最適化に使われるので、SEO対策を行う上で、robots.txtの設定方法や、記述方法について知っておくべきでしょう。
このページではrobots.txtの機能やSEO上の効果、設定方法について解説します。
robots.txtがクローラーへ命令(指定)できること
最初にrobots.txtの機能や、クローラーへ指示できることについて簡単に説明します。
アクセスの許可、クローラーの拒否
robots.txtで最も用いられるクローラーへの命令文は、クローラーからのアクセスを許可するかどうかです。クローラーの種類別にアクセスを許可する『allow』、アクセスを止める『disallow』が用いることができます。
disallowとnoindexタグとの違い
『disallow』と『noindexタグ(検索エンジンに表示させないためのメタタグ)』が混合してしまう方は少なくありません。『noindexタグ』はページ内で設定するため、クローラーがページに回遊(アクセス)して初めて、検索エンジンに表示させるかどうかを判断します。
一方、『disallow』はアクセスそのものを拒否するためのものです。まだインデックスされていないページには、『disallow』、すでにインデックスされたものに『noindexタグ』を用いるのが一般的かと思われます。
※この点について『noindexタグと併用しない』にて詳しく後述します。
サイトマップ(sitemap.xml)の格納先
サイトマップ(sitemap.xml)が保存された階層を指定することもできます。指定することでクローラーがサイトマップの場所を認識するので、クローラビリティの向上に繋がります。
noindexタグの設定もできる?
『noindexタグ』はサイト内の<head>タグ内で設定するのが一般的ですが、robots.txtで設定しても効果があると言われております。
robots.txtのSEO上の効果
以上がrobots.txtがクローラーへ指定できる項目になりますが、SEO的には『disallow』を指定してあげることで評価の低いページへのクロールを減らし、重要なページへのクロールに集中しやすくなり、結果、サイト全体が評価されやすくなります。
また、sitemap.xmlの場所の指定ができるので、クロールされる頻度が高まりやすくなります。
robots.txtの設定方法
ではrobots.txtはどのように設定すれば良いのでしょうか?
ファイル名
まずテキストエディタなどを介して、名前が『robots.txt』のファイルを作成してください。
よくあるファイル名の間違い
注意していただきたいのが、sが欠けている(『robot.txt』)、大文字小文字の間違えている(『Robots.txt』)など、ファイル名を間違えないように注意しましょう。
保存場所
ファイルの下書きができたら、サーバーへアップロードしましょう。保存場所はドメイン直下に設置するのが一般的です。
記述方式
ファイルの中には、ロボットの種類、対象のページまたはディレクトリ、アクセスするかしないかを記述します。
- User-agent:ロボットの種類
- 全てのクローラーを対象にする場合:User-agent : *
- Googlebotだけ対象の場合:User-agent : Googlebot
- バイドゥだけ対象の場合:User-agent : Baiduspider
アクセス(クロール)する、しない
- アクセスを拒否する場合:Disallow
- アクセスを許可する場合:allow:
サイトマップの格納先
sitemap.xmlの格納先を指定する際には、省略せず絶対パスでURLを記述します。
【例】
Sitemap : https://ドメイン名/sitemap.xml
robot.txtの記述方法の例
続いて具体的な記述方法を紹介します。
全ページへのモバイル用クローラーからのアクセスを止める
User-agent: Googlebot-Mobile
Disallow: /
特定のディレクトリ(階層)への、全てのクローラーからアクセスを止める
User-agent: *
Disallow: /marketing/※『marketing』という名前の階層以下のページ全てのアクセスを止める場合を想定しております。
特定のページへの全てのクローラーからのアクセスを止める
User-agent:*
Disallow: /marketing/columns4※URLが『http://ドメイン/marketing/columns4/』のページへのアクセス禁止を想定しております。
ディレクトリ単位でnoindexを設定する
User-Agent: *
Noindex: : /marketing/※『marketing』という名前の階層以下の全ページのnoindexの指定を想定しております。
robots.txtの記述の内容にエラーがないか確認するには?
『robots.txt』に記述した内容に間違いがないか確認するにはどうすれば良いのでしょうか?
旧サーチコンソールのrobots.txtテスターへアクセスする
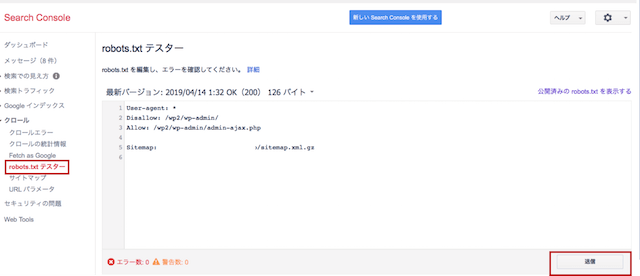
まず旧サーチコンソールへ移動し、『クロール』の『robots.txtテスター』へ進み、送信ボタンを押してください。
エラー、警告がないか確認する
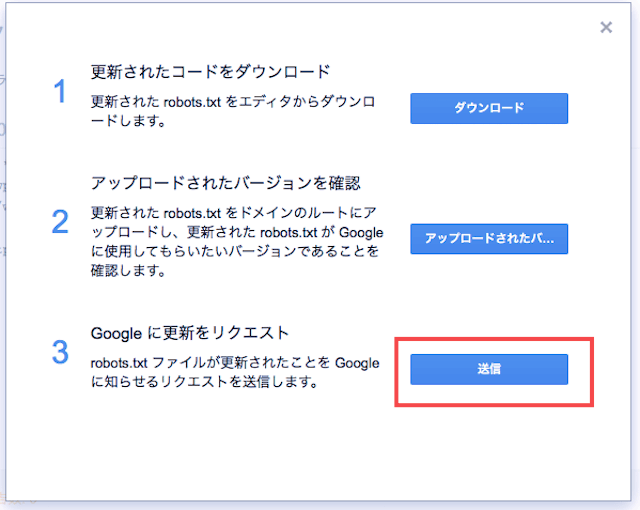
『1、更新されたコードをダウンロード』、『2、アップロードされたバージョンを確認』『3、Googleに更新をリクエスト』の3つがありますが、3の送信を押します。
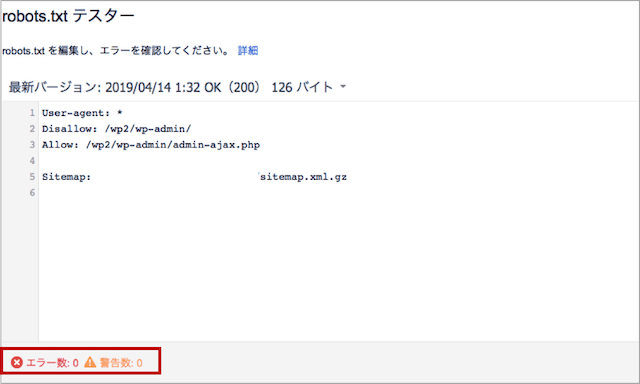
最初の画面に戻ります。エラー数、警告数が両方とも0であれば問題ありません。
robots.txtの利用上の注意点
最後にrobots.txtを使用する上での注意点を紹介します。
効果は絶対ではない
クローラーの中には、robots.txtの命令を無視することもあります。またrobots.txtで指定したことがすぐ反映されるわけではないので、その点を踏まえた上で利用しましょう。
disallowを設定してもユーザーはアクセスできる
またdisallowを設定しても、クローラーからのアクセスは拒否できますが、ユーザーはrobots.txtを閲覧できます。
noindexタグと併用しない(インデックス済のページにdisallowは使用しない)
『robots.txt』のdisallowは『noindexタグ』と同様、低品質なページに対して用いますが、併用してはいけません。
先ほどお伝えした内容と重複しますが、すでに検索結果に表示(インデック)されたページに対して、disallowを設定しても、クローラーがページを辿ってこなくなるだけで、検索結果には表示され続けるからです。
インデックスされた状態でdiallowによってクローラーのアクセスを拒否すると、いざnoindexタグを設定しても、クローラーがそのページをアクセスしないため、クローラーにnoindexタグを指定したことを伝えることができず、indexされたままになってしまいます。
そのため既にインデックス済みの低品質ページに対しては、noindexやcanonicalタグ、301リダイレクトなど別の方法で対応しましょう。
【参考記事】